
GPU加速的基数排序算法实现与优化
人工智能
2024-05-22 01:30
696
联系人:
联系方式:
随着大数据时代的到来,数据处理的需求日益增长,传统的排序算法在面临大规模数据时往往效率低下。基数排序作为一种非比较型整数排序算法,其时间复杂度可以达到线性级别,即O(n),这使得它在处理大规模数据时具有显著优势。然而,基数排序算法在传统CPU上的实现仍然存在性能瓶颈。近年来,随着图形处理器(GPU)技术的飞速发展,利用GPU强大的并行计算能力来加速基数排序成为了一个值得研究的问题。
本文首先介绍了基数排序的基本原理和步骤,然后分析了在GPU上实现基数排序的优势和挑战。接着,详细介绍了如何在CUDA平台上设计和实现基数排序算法,包括数据的分块、并行化处理等关键步骤。为了进一步提高排序效率,本文还探讨了多种优化策略,如减少全局内存访问延迟、合理利用共享内存等。通过实验验证了所提出方法的有效性,并与传统CPU实现的基数排序进行了性能对比。
一、引言
随着信息技术的快速发展,数据量呈爆炸式增长。如何高效地对海量数据进行排序成为了一个亟待解决的问题。基数排序作为一种高效的排序算法,在处理大规模数据时具有明显优势。然而,传统的CPU实现方式在面对超大规模数据时仍然显得力不从心。幸运的是,GPU的出现为解决这一问题提供了新的可能。
二、基数排序算法概述
基数排序是一种非比较型整数排序算法,其基本思想是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。由于每次都是针对单个位进行排序,因此基数排序的时间复杂度可以达到线性级别,即O(n)。
三、GPU加速基数排序的优势与挑战
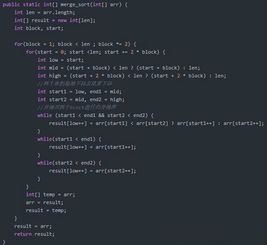
相比于CPU,GPU拥有更多的核心和更高的并行计算能力,这使得它在处理大规模数据时具有显著优势。然而,GPU编程也面临着诸多挑战,如全局内存访问延迟高、线程间通信困难等问题。因此,如何充分利用GPU的计算资源并克服这些挑战是设计高效基数排序算法的关键。
四、基于CUDA的基数排序设计与实现
本文在CUDA平台上设计和实现了基数排序算法。首先将数据分块并分配到各个线程块中进行处理;然后采用并行化的桶排序算法对每个位的数字进行排序;最后通过多次迭代完成整个排序过程。为了提高排序效率,本文还采用了多种优化策略,如减少全局内存访问延迟、合理利用共享内存等。
五、实验结果与分析
为了验证所提出方法的有效性,本文进行了大量实验并与传统CPU实现的基数排序进行了性能对比。实验结果表明,基于CUDA的基数排序算法在处理大规模数据时具有明显的速度优势。通过进一步优化策略的实施,可以进一步提高排序效率。
六、结论与展望
本文提出了一种基于CUDA平台的基数排序算法并进行了详细的设计与实现。通过实验验证了该方法在处理大规模数据时的有效性。未来工作中将进一步探索更多优化策略以提高排序效率并拓展到更多应用场景中。
随着大数据时代的到来,数据处理的需求日益增长,传统的排序算法在面临大规模数据时往往效率低下。基数排序作为一种非比较型整数排序算法,其时间复杂度可以达到线性级别,即O(n),这使得它在处理大规模数据时具有显著优势。然而,基数排序算法在传统CPU上的实现仍然存在性能瓶颈。近年来,随着图形处理器(GPU)技术的飞速发展,利用GPU强大的并行计算能力来加速基数排序成为了一个值得研究的问题。
本文首先介绍了基数排序的基本原理和步骤,然后分析了在GPU上实现基数排序的优势和挑战。接着,详细介绍了如何在CUDA平台上设计和实现基数排序算法,包括数据的分块、并行化处理等关键步骤。为了进一步提高排序效率,本文还探讨了多种优化策略,如减少全局内存访问延迟、合理利用共享内存等。通过实验验证了所提出方法的有效性,并与传统CPU实现的基数排序进行了性能对比。
一、引言
随着信息技术的快速发展,数据量呈爆炸式增长。如何高效地对海量数据进行排序成为了一个亟待解决的问题。基数排序作为一种高效的排序算法,在处理大规模数据时具有明显优势。然而,传统的CPU实现方式在面对超大规模数据时仍然显得力不从心。幸运的是,GPU的出现为解决这一问题提供了新的可能。
二、基数排序算法概述
基数排序是一种非比较型整数排序算法,其基本思想是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。由于每次都是针对单个位进行排序,因此基数排序的时间复杂度可以达到线性级别,即O(n)。
三、GPU加速基数排序的优势与挑战
相比于CPU,GPU拥有更多的核心和更高的并行计算能力,这使得它在处理大规模数据时具有显著优势。然而,GPU编程也面临着诸多挑战,如全局内存访问延迟高、线程间通信困难等问题。因此,如何充分利用GPU的计算资源并克服这些挑战是设计高效基数排序算法的关键。
四、基于CUDA的基数排序设计与实现
本文在CUDA平台上设计和实现了基数排序算法。首先将数据分块并分配到各个线程块中进行处理;然后采用并行化的桶排序算法对每个位的数字进行排序;最后通过多次迭代完成整个排序过程。为了提高排序效率,本文还采用了多种优化策略,如减少全局内存访问延迟、合理利用共享内存等。
五、实验结果与分析
为了验证所提出方法的有效性,本文进行了大量实验并与传统CPU实现的基数排序进行了性能对比。实验结果表明,基于CUDA的基数排序算法在处理大规模数据时具有明显的速度优势。通过进一步优化策略的实施,可以进一步提高排序效率。
六、结论与展望
本文提出了一种基于CUDA平台的基数排序算法并进行了详细的设计与实现。通过实验验证了该方法在处理大规模数据时的有效性。未来工作中将进一步探索更多优化策略以提高排序效率并拓展到更多应用场景中。

